
Le développement de biens et services centrés utilisateurs invite les organisations à améliorer les méthodes, outils et processus de recherche utilisateur. Pour ce faire, des outils pensés pour faciliter les activités de recherche intègrent progressivement les processus de travail des équipes.
Daniel Pidcock, chercheur spécialiste en UX, a puisé dans les difficultés rencontrées par ses équipes au quotidien pour développer une méthodologie et un outil destiné à capitaliser efficacement les données de la recherche utilisateur : Glean.ly.
Le premier outil dédié à l’Atomic Research
Qui de mieux pour concevoir un outil basé sur une méthodologie que celui qui en est le créateur ? Lors de sa conférence sur l’Atomic Research à l’UX Brighton en 2018, Daniel Pidcok a dévoilé l’outil qu’il a pensé pour faciliter la recherche utilisateur avec ces mots : “What if our UX knowledge was in a searchable and shareable format?” (“Et si l’ensemble de nos connaissances UX était accessible sous un format facilement recherchable et partageable ?”).
Fondée sur la base théorique de l’Atomic Design, l’Atomic Research est une méthodologie visant à étudier un objet en le découpant en plusieurs éléments pouvant être examinés à la fois sous leur forme primaire et de façon relative par rapport à d’autres éléments.

Si l’Atomic Design entend identifier les éléments composant une structure visuelle donnée, l’Atomic Research reprend quant à lui la structure de la synthèse d’une recherche utilisateur pour catégoriser les informations obtenues et les lier entre elles.
Les expériences (questionnaires, entretiens) engendrent des faits et objectifs neutres (80% des utilisateurs ne cliquent pas sur le bouton rouge), qui nous poussent à supposer des insights (“les utilisateurs préfèrent les boutons verts”) desquels nous pouvons déduire des recommandations (“il faut remplacer les boutons rouges par des boutons verts”).
Glean.ly s’appuie sur cette structure pour faciliter le travail de l’UX Researcher en lui permettant de naviguer au sein d’un ensemble d’informations ordonnées et interconnectées.
Les fonctionnalités clés de l’outil
Nous l’avons vu, l’outil repose sur l’adaptation du modèle de l’Atomic Research. Les fonctionnalités clés de Glean.ly sont donc par nature des moyens de valoriser l’interconnexion des données de la recherche utilisateur.
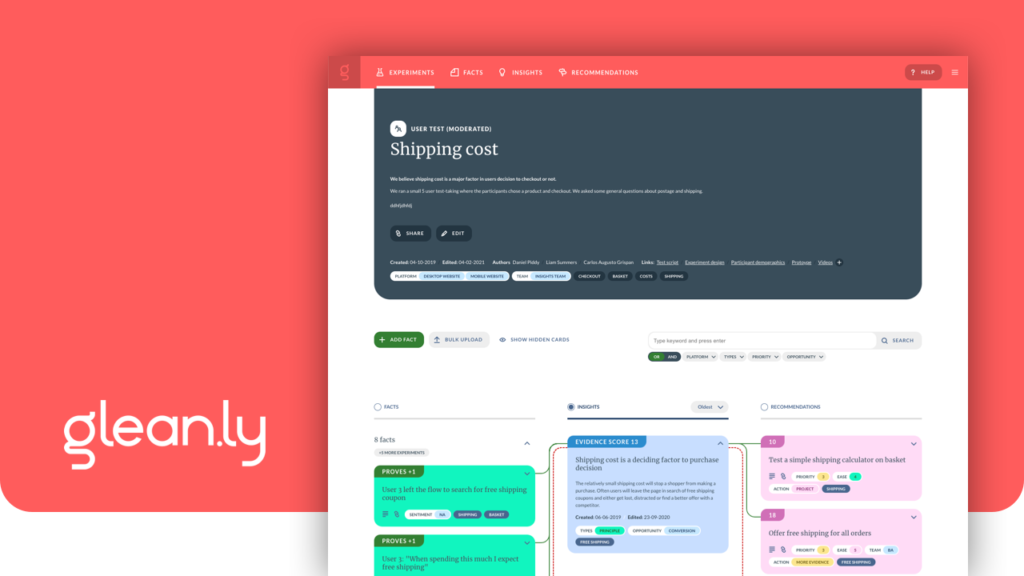
Cartes interconnectées
Chaque élément des étapes de l’Atomic Research est représenté sous forme de carte. Chaque carte est reliée à celle qui la justifie ainsi qu’à celle qu’elle permet de déduire.
Grâce à cette structure, les recommandations issues d’une recherche utilisateur sont justifiées par des faits objectifs qui permettent de valider ou non des hypothèses appelées insights, sur la base desquels des recommandations sont réalisées puis testées.
Les cartes interconnectées favorisent une démarche itérative, puisque les tests utilisateurs effectués d’après les recommandations faites par l’outil alimentent une série de faits qui entameront un nouveau cycle de la recherche utilisateur.
Enfin, les éléments d’une étape peuvent être rassemblés en une liste ; l’arborescence au sein de laquelle un élément se trouve apparaît lorsque l’on clique sur une carte.

Un classement intelligent des informations
Pour améliorer la pertinence des données collectées, Glean.ly a conçu des métadonnées triables sous forme de filtres, tags et scores :
Les filtres sont personnalisables par l’administrateur et concernent par défaut :
- Les sentiments (positif, neutre, négatif)
- Le type de l’insight (principe, conseil, transitoire)
- La priorité (classée de 1 à 5)
- La facilité de mise en œuvre (classée de 1 à 5)
- L’échelle de mise en œuvre (d’une personne à toute l’entreprise)
- Le statut de la recommandation (rejetée, complétée, approuvée, réutilisable…)

Les tags correspondent à des étiquettes – elles aussi personnalisables – permettant de naviguer entre les données grâce à une simple recherche précise. Il est également possible de se rendre dans le menu des tags et de trouver le nombre d’occurrences qui y sont associées.

Le système de score permet de préciser les informations récoltées : au coin de chaque carte, un score correspond à la somme des cartes antérieures qui la prouvent ou l’infirment.

Par exemple, si 3 insights valident une recommandation, mais que 2 insights l’invalident, le score de la recommandation sera de : 1.
Import/Export
Entrer manuellement des dizaines de faits peut être chronophage. Glean.ly permet de les importer sous 3 formats :
- Aux formats .XLS, .XLSX et .CSV. Les feuilles de calcul peuvent être importées dans l’outil, qui héberge notamment Microsoft Excel, Miro et Maze.ermettant ainsi l’intégration avec Microsoft Excel, autres tableurs ainsi qu’avec Miro et Maze ;
- L’extension Glean.ly (disponible sur le Chrome Web Store) offre la possibilité de convertir un contenu textuel provenant d’Internet en fait ;
- L’intégration Zapier (payante) permet d’importer des données directement dans l’outil mais la prise en main peut être fastidieuse.

Invitation membre
Glean.ly permet d’inviter des collaborateurs sur votre espace à partir de leur adresse email. Vous pouvez leur attribuer l’un de ces trois statuts :
- View Only (“lecture seule”) : les nouveaux collaborateurs peuvent consulter votre annuaire d’expériences, faits, insights et recommandations ;
- Contributor (“contributeur”) : en plus d’un accès aux fonctionnalités du statut précédent, les invités pourront entrer des informations dans l’annuaire ;
- Administrator (“administrateur”) : l’invité dispose de l’ensemble des droits ; il peut même personnaliser les filtres, gérer l’abonnement et modifier les tags.

Notre avis d’expert
Un outil spécifique
L’outil est très précis sur la recherche utilisateur ; c’est une force, mais peut aussi être une faiblesse selon l’axe de travail choisi.
Centré sur la recherche utilisateur, l’outil est moins facilitant pour le reste du processus comme l’idéation ou le prototypage. Par ailleurs, l’intégration avec d’autres outils n’est pas toujours fluide ; la navigation entre ces derniers implique une perte de données, bien que Glean.ly valorise l’interconnexion des cartes dans sa promesse de vente.
Nous l’avons vu, si l’on prend uniquement en compte la recherche utilisateur (l’essence même de sa conception), l’outil est d’une efficacité redoutable.
Une expérience utilisateur prometteuse
L’expérience utilisateur est plutôt satisfaisante dans l’ensemble, bien qu’elle puisse être améliorée, par exemple en fluidifiant le processus de création d’éléments. Le système de points attribué aux cartes n’est pas encore optimal, puisqu’il ne prend pas en compte la pondération, c’est-à-dire le poids de chaque information dans la justification d’une autre.
Nous ne pouvons pas passer à côté des gifs s’affichant au chargement des pages, ajoutant un côté “fun” à l’outil.
Une adaptation des normes RGPD à respecter
Cependant, il est clairement souligné que l’outil ne répond pas aux exigences du RGPD. Osons imaginer que Glean.ly sera bientôt compatible avec les normes européennes pour conquérir un marché qui ne lui est sûrement pas indifférent.
Un recueil et une capitalisation efficace
La récolte des faits depuis l’extension Chrome est un réel game changer dans une recherche utilisateur.
Par ailleurs, grâce à l’interconnexion et les filtres, l’outil promet une capitalisation accrue des informations et un gain de temps considérable. Il palie ainsi une navigation chronophage dans des masses informes de données. L’information est fluide, transparente, accessible et consultable par les équipes d’UX Researcher, ainsi que des métiers requérant de la visibilité sur le processus de recherche.
Un potentiel de taille
La recherche utilisateur est au cœur du Design Thinking. Faite avec rigueur, elle constitue un avantage concurrentiel de taille. C’est en tout cas le pari de l’Atomic Research, dans laquelle Glean.ly puise ses fonctionnalités. L’enjeu majeur de son évolution au cours des prochaines années ? Devenir incontournable dans la Research Ops.
Vous souhaitez essayer l’outil ou être accompagné·e·s par nos équipes Acceleration Tactics ?






