

La visualisation de données (plus connue sous la version anglophone data visualization) n’est aujourd’hui plus à présenter. Omniprésente dans notre environnement quotidien, la data visualization est pratiquée depuis des centaines d’années. Avec l’avènement de l’ère du numérique, il est aujourd’hui possible de créer très rapidement (et même dynamiquement) des visuels pour représenter la donnée :
- Plans des transports en commun
- Courbes d’évolution d’actions boursières
- Jauges de performance
- “Camemberts” de répartition
- Infographies
- etc…

Ce premier constat étant fait, voyons ensemble pourquoi la data visualization devrait être utilisée (et donc maîtrisée) dans le quotidien professionnel de chacun d’entre nous.
La première réponse venant à l’esprit est de se dire que la data visualization permet de faciliter la communication. C’est vrai, l’un des rôles principaux de la data visualization est de simplifier et résumer de nombreuses données pour les rendre accessibles à tous.
On a l’habitude de dire que 90% de l’information transmise au cerveau est visuelle et que le cerveau est capable de traiter une image 60 000 fois plus vite qu’un texte. Même si ces chiffres ne sont pas exacts et fondés, tout le monde semble s’accorder sur ce point : Il est plus fatiguant de lire un tableau de chiffres plutôt qu’un simple graphique.
Illustrons le point précédent avec un tableau (ne contenant que 8 lignes et 4 colonnes) et un graphique associé.
Les valeurs représentées correspondent au nombre d’utilisateurs fictifs (en millier) de certains assistants graphiques (appelés packages) du langage python.
En moins de 5 secondes, en ce basant sur le tableau, quel package a connu la meilleure progression en terme d’utilisateurs sur ces dernières années ?

Même question en se basant cette fois sur le graphique adapté à la problématique présentée :

Notre crédibilité en présentation dépend de la facilité avec laquelle nous arrivons à faire comprendre à l’auditoire notre message. Comme nous pouvons le constater, il est plus aisé de convaincre une assemblée que le package « Altair » a eu la plus grande croissance en se basant sur le graphique plutôt que sur le tableau.
Le second rôle, non-négligeable, de la data visualization est qu’elle permet de mieux comprendre le comportement de ces données. Elle peut également permettre de mettre en avant des éléments peu visibles (ou invisibles) à partir de données brutes ou de statistiques simples (moyennes, variances, corrélations, etc.).
Pour illustrer ce propos, nous allons exposer le cas d’étude du statisticien Francis Anscombe (1918–2001). Le dataset mis au point représente 4 groupes de données (I, II, III et IV) étudiant l’interaction entre deux variables (x et y). Il permet de démontrer la nécessité de la visualisation dans l’analyse de données. Le voici en détail :

À partir des données brutes il est très difficile, ou même impossible, d’estimer rapidement la répartition des différents jeux de données. Les statistiques de base (présentes à droite) n’aident pas à distinguer les différents jeux de données. Ce n’est bien qu’en visualisant les données que l’on se rend compte des différences :

Si ces petits exemples vous ont convaincus de l’utilité de la data visualization, il ne reste qu’à se lancer !
Cette série d’articles (moins de 5 min de lecture) présentera les principaux risques, meilleures pratiques et conseils pour améliorer l’ensemble de vos visualisations !
Si vous souhaitez être accompagné par nos experts data dans vos démarches de visualisations de données, n’hésitez pas à nous contacter.
Rédigé par Eliot Moll, Consultant Data Driven Business
Thanks to Max Mauray, Nawel Medjkoune, Nicolas Risi, and Clément Moutard.

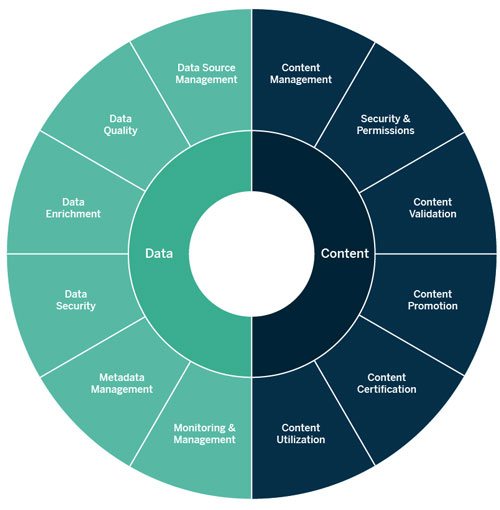
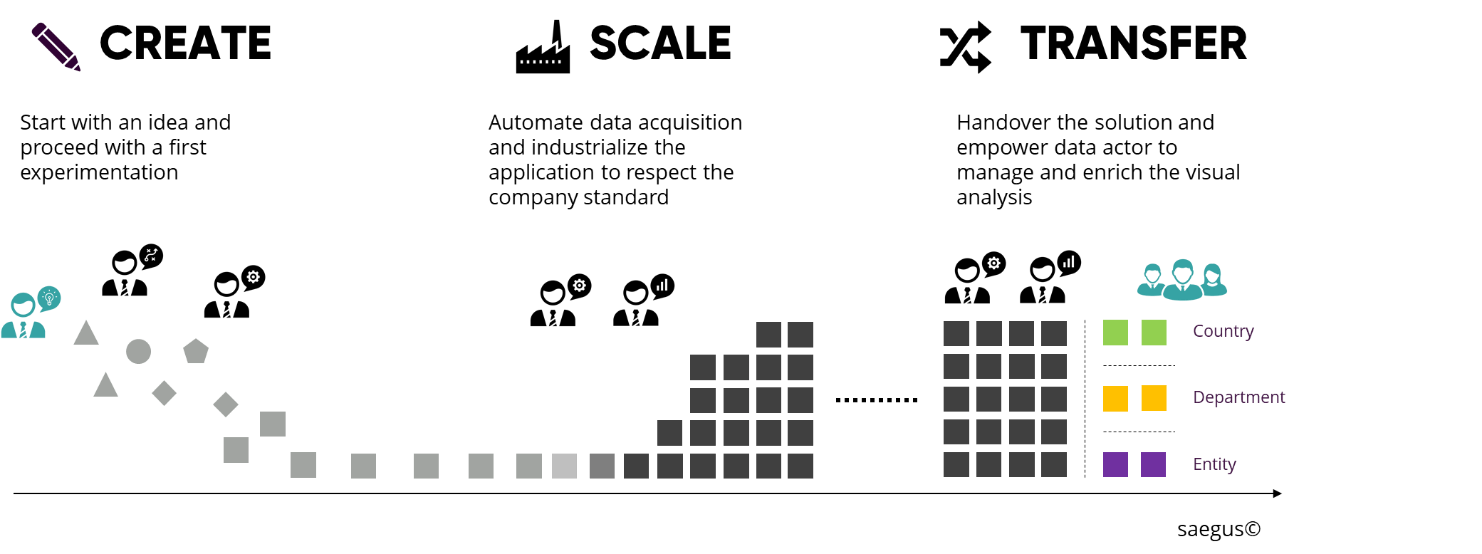 You’ll see real value when Tableau is broadly deployed across the company, but only if your governance framework can ensure accurate data and analytics content. It becomes more than data visualization—it’s a communication system that will link the whole company in making better decisions.
You’ll see real value when Tableau is broadly deployed across the company, but only if your governance framework can ensure accurate data and analytics content. It becomes more than data visualization—it’s a communication system that will link the whole company in making better decisions.